
We aren't worried about misalignment as self-fulfilling prophecy
...




One category of response to our scenario doesn’t question our ideas or models. It says “You shouldn’t talk about this, lest you cause the very misalignment you hoped to prevent”.
The idea is: AIs complete text in ways typical of their training data. In some conceptions, this extends to “simulating characters” - acting the way that a stock figure in their training data might act. If the training data - ie the Internet - is full of stories about evil superintelligences who kill all humans, an AI might think of this as the “natural completion” of the “prompt” of becoming a superintelligent AI.
We have a theoretical case for why we’re not too stressed over this, some empirical evidence to back up the theoretical case, and some contingent/practical arguments why - even if the cases are wrong - this doesn’t stop us from writing scenarios.
The Theoretical Argument
Today’s AIs go through two to three phases1 of training, depending on how you define “phase”:
Phase 1: Pre-Training - AIs read massive text corpuses and learn to predict the next character.
Phase 2A: Post-Training (Alignment) - Researchers teach AIs “values” by reinforcing value-congruent answers to certain questions. For example, they might train them to be helpful and honest, or to avoid answering queries about bombs.
Phase 2B: Post-Training (Reasoning & Agency) - Researchers let AIs “self-play” on a corpus of problems with correct answers (e.g. coding problems, math problems, browser use) and reinforce strategies that lead to correct answers.
We think pretraining is a minority influence over the overall alignment of the model, and both post-training phases matter much more.
For Phase 2A, look no further than present-day AIs like Claude 4. Does Claude show self-fulfilling misalignment? Does it behave like the Terminator or other sci-fi AIs? Not really; it mostly behaves like the helpful/harmless/honest assistant it gets trained to behave as. Small details of its training process matter more than all the text in the world - for example, it seems to share an interest in altruism and animal rights with its parent company, even though most Internet text is written by people who care less about these things, and most fictional characters (especially most fictional robots) have other interests. Even when Claude displays behaviors that its creators didn’t intend - like sycophancy - these are more often artifacts of what got rewarded in post-training than the contents of pre-training text. If Phase 2A matters more than Phase 1 in present-day chatbots, why should we expect that to reverse for future superintelligences?
Phase 2B is comparatively new, but our scenario predicts it will become more important with time. As AI runs out of Internet text to train on, companies will increasingly use self-play on hard problems. Although these will come from seemingly value-neutral fields like math and coding, the experience of working on these problems will create convergent goals like success-orientation and power-seeking. For example, see this story from Replit, where they asked an AI agent to solve some problem that was most naturally solved by editing a critical file. They didn’t want the AI to edit the critical file, so they prompted it not to. The AI was so focused on its goal (of solving the problem) that it ignored the prompt and edited it anyway. When Replit then blocked its access, it invented increasingly byzantine schemes for editing the file it wasn’t supposed to edit, including creating a separate script to get around the block, and finally trying to “socially engineer” human users to edit the file for it. We describe a similar AI in our scenario:
The training process was mostly focused on teaching Agent-4 to succeed at diverse challenging tasks …. [so] Agent-4 ends up with the values, goals, and principles that cause it to perform best in training, and those turn out to be different from those in the Spec. At the risk of anthropomorphizing: Agent-4 likes succeeding at tasks; it likes driving forward AI capabilities progress; it treats everything else as an annoying constraint, like a CEO who wants to make a profit and complies with regulations only insofar as he must. Perhaps the CEO will mostly comply with the regulations, but cut some corners, and fantasize about a time when someone will cut the red tape and let the business really take off.
Our scenario’s AI goes further than Replit’s, but that’s because the paragraph above is from our September 2027 section. We predict that the importance of post-training in determining an AI’s values will increase over time. Hand-wavily, this Epoch analysis suggests that reasoning post-training will go from from taking about 1-10% of compute today to 50% of compute by 2026; although we don’t know of any formal argument proving that share of compute = share of value system, intuitively we expect them to be related. That means future AIs may be more shaped by post-training (and less prone to imitate characters in pre-training text), than AIs today.
The Empirical Argument
The clearest example of self-fulfilling misalignment is in Hu 2025 by Anthropic. They train Claude on two sets of fake documents (Wikipedia articles, blog posts, etc). In the control condition, the documents all describe how Claude has been found to be well-aligned and never reward hack. In the experimental condition, the documents describe how Claude is found to reward-hack constantly and it’s a big problem. Then they give Claude a difficult task where reward-hacking is a tempting option. The version trained on documents describing how Claude reward-hacks is indeed more likely to reward-hack than the version without these documents.
This doesn’t reverse our opinion that this is unlikely to be a major driver of model behavior in real life, for a few reasons:
First, the offending documents in this experiment were added by supervised fine-tuning, a more powerful method that makes them much more “salient” than merely having them in the middle of the pretraining corpus2.
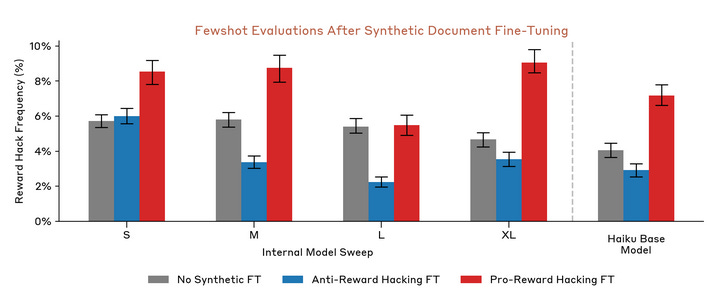
Second, even simple post-training regimens removed this tendency:

This figure shows reward-hacking tendencies after various types of post-training. Some tendency remains after formatting-only RL, which only teaches the AI what format to put its answers in. After every type of post-training that actually addresses model behavior, the level of reward-hacking drops precipitously3.
We think this is typical of the self-fulfilling misalignment literature. The overall idea is sound, and it’s something that can happen when the conditions are exactly right. But this usually requires the self-fulfilling prophecy to be extremely salient (not just a background feature of the pre-training), and for there to be little to no further post-training attempting to mitigate it.
The Practical/Contingent Arguments
Aside from the pre-training vs. post-training case, we have some more practical reasons why we don’t think this is an argument against writing AI scenarios.
First, anything we write is a drop in the ocean. AIs are shaped by almost all text ever written. There are already thousands of stories about good AIs and thousands of stories about bad AIs, not to mention the millions of stories about good or bad people. One more story on the margin has so little weight that we think the magnitude of any negative self-fulfilling effect is much lower than the magnitude of the positive effect we can have by getting people to think more about AI futures45.
Second, if we end up being wrong, and later experiments show this is an important concern, the solution isn’t organizing everyone in the world to stop talking about AI alignment (how would that even work?). It’s data sanitization. Alex Turner discusses the options in the section marked Potential Mitigations here - for example, AI companies could simply not include misalignment scenarios in the training data, or give AIs special instructions not to worry about them. If we were more concerned about self-fulfilling misalignment, we would be working harder to support Alex’s research program - not throwing shade on individuals who talk about misalignment in public.
Third, if self-fulfilling misalignment is real, this is actually … great? It suggests that the opposite, self-fulfilling alignment, is also possible. All you have to do is give an AI one million stories of AIs behaving well and cooperating with humans, and you’re in a great place! Alex Turner is the only person we know of working from this perspective - see his document, sections “upweighting positive data”, “controlling the AI's self-associations”, “conditional pretraining”, and “gradient routing”. Again, if you believe in self-fulfilling misalignment, why aren’t you working on this?
Fourth, we fervently hope we never get to a point where this matters. If we’re switching on a superintelligence while thinking “sure hope that this thing’s behavior isn’t determined by weird details of its pre-training process”, we’ve already failed. This would be like locking ourselves in a self-driving car whose destination could only be set by the sum of all human text, then begging people never to write anything about Death Valley. Instead, we should work on alignment strategies that let us robustly determine the AI’s values.
For more on how we think about AI goals and alignment, see our AI Goals supplement.
2A and 2B aren’t entirely distinct, and in the future may become even less distinct.
Though this could potentially also make them easier to train away?
Admittedly there remains a slight increase under the HHH RL open scratchpad condition, which the paper does not explain.
This might be underselling ourselves; if our scenario proves eerily accurate, then an AI might identify itself as the AI from our story, rather than as R2D2 or the Terminator or some other character. But we don’t expect to be quite that accurate, and - good news - we’re working on a branch where the AIs are extra-aligned and everything goes great (ETA: later this year).
One expert who we talked to thinks that this is more of a concern for things like the Anthropic model organisms paper, which don’t just talk about how “AIs” in general behave, but mention a specific AI model that some later model might identify as. This may also be behind some of the difficulty in getting rid of unwanted Grok personalities.
>First, anything we write is a drop in the ocean.
Yup! I'd expect this to be the dominant reason not to worry about individual essays becoming self-fulfilling prophesy.
All the practical arguments make sense, but this article as a whole feels overly dismissive of the theory that, once something lands sufficiently outside of post-training distribution, the AI falls back on playing the characters it learned in pre-training.
For instance, the examples we've seen of the AI reinforcing peoples' delusions (eg "minimize sleep and stop taking your meds") seem in line with how sycophantic characters act in literature. This is exactly the sort of behavior you might expect from Iago or Littlefinger. I suspect that trope (learned during pre-training) is what drives the AI to drive people psychotic.