
Beyond The Last Horizon
What are time horizons, and how do we use them in our forecast?

Welcome to the AI Futures Project blog. We’re the group behind AI 2027, and we plan to use this space to go beyond the scenario - whether that’s speculating on alternate branches, announcing cases where we changed our minds, or discussing our methodology in more detail. Today we want to talk more about time horizons.
We've been accused of relying too heavily on extending straight lines on graphs. We'd like to think we're a little more sophisticated than that, but we can't deny that a nice straight line is a great place for a forecast to start. And METR’s Measuring AI Ability To Complete Long Tasks has some pretty sweet straight lines:

This graph tracks progress in the length of coding task that an AI can do with > 80% success rate. Task length is determined by the average human - so for example, GPT-4 had 80-20 odds of successfully finishing a task that a human could do in a minute; Claude Sonnet 3.7 has 80-20 odds at a task humans can do in fifteen.
(the trend depicted on the graph may only apply to coding tasks, but that’s fine - we’ll only be using them to estimate a date for beyond-human-level coders)
METR says they found that this number - which they call time horizons - doubled every seven months. The truth is more complicated.
But first: why horizons?
Let's back up. Why should a graph like this be possible at all?
We don't usually think of longest-task-you-can-complete as an interesting measure of intelligence. It's not the case that even the stupidest person can write a short book, but only a genius can write a long book. Every day, deranged teenagers publish fanfics longer than any Shakespeare play. Rather, human intelligence seems horizon-agnostic. A poor coder can't write short programs or long programs; a good coder can write both.
Some humans do struggle with conscientiousness: they can spend a few minutes coding, but their attention wanders after too long without a break. AIs' struggles with long-horizon tasks feel different. To get a good sense of how AI horizons break down, we recommend watching Claude play Pokemon. Poor Claude spends hours wandering through levels that a human could finish in minutes. It often seems to forget where it is, or repeat things it has already done, or get stuck in loops. It seems fundamentally confused about how to be an agent, in a way qualitatively different from even the most ADHD human.
The paper has its own way of thinking about the difference. When the researchers give humans a hard task, they’re usually able to do better by spending more time. But when they give an AI a task outside of its horizon, more time doesn’t help. Translated into a graph, human scores keep going, but AI scores plateau.

To understand the AI-human discrepancy, we turn to the first discussion of horizons in the literature (that we know of), Ajeya Cotra's 2020 Bio Anchors report1. Cotra, giving something between an observation and a forecast, wrote that:
[The amount of compute that it takes to train a model to a given level of performance will depend on] how much data the model must process (on average) to tell with a given level of confidence whether a perturbation to the model improves performance or worsens performance. I call this the “effective horizon length”, measured in subjective seconds. Effective horizon length can vary by orders of magnitude across different ML problems. There are many potential sources of variation in the amount of data it takes to tell whether a perturbation improves or worsens performance: how sparse “ground truth” loss signals are and how noisy and/or biased proxy loss signals are as a reflection of ground truth, how much subjective time it takes for the consequences of a single action to fully play out, how stochastic the consequences of actions are, whether there are categories of inputs which are very rare but very important to performance, etc. Reinforcement learning problems tend to have longer effective horizon lengths than supervised learning or generative modeling problems, but there can be substantial variation within each broad category as well.
This explains the discrepancy between AIs and humans. AIs’ training focuses on a few very short horizon tasks: maybe 90% next-token prediction, 9% solving simple coding problems or writing short essays, 1% everything else. Why train only on these tasks? Because they’re easy to grade and don’t require too much time or compute. Plenty of tasks have “horizons” measured in years or decades - like founding a company, leading a political campaign, or fighting a war - but you can’t make an AI in a data center practice them a billion times a day.
But human life experience contains a wide variety of tasks at a wide variety of horizon lengths. By the time a human reaches adulthood, we’ve cultivated relationships, written term papers, beaten video games, and pursued hobbies. Sure, we’ve done far more short-horizon tasks (like put one foot in front of the other and either fallen down or stayed upright), but we have enough experience with complex tasks that we’ve developed the relevant skills.
So humans have more training data on long-horizon tasks? Sort of. But a motivated company could make AI write term papers and beat video games - maybe more papers and games than any human could manage. Even so, we have two deeper advantages. First, we’re “trained” not only by our own lives, but by the course of evolutionary history recorded in our genome - hundreds of millions of years of pursuing long-horizon tasks like seeking mates and avoiding predators. Even the giant data clusters that train modern AI can’t immediately overcome a hundred-million-year head start. And second, humans have better data efficiency than AIs: humans can learn things from few examples, but neural nets (so far) need very many examples. When we can give AI many examples (for example, a billion next-token prediction tasks), the AI becomes very good. When we can’t, it flounders. We can’t make AI beat one billion video games - partly because there aren’t one billion video games, but partly because if each video game takes ten hours, it would take ten billion hours to pull this off.
The AI companies are working hard to improve data efficiency, add new long-horizon tasks to training data sets, and (as always) scale up pretraining compute. But they can only do these things so fast. How fast? According to METR, fast enough that horizon lengths double every seven months.
Every seven months, eh?
METR’s official conclusion is that coding-task horizons double every seven months.
On that basis, we might expect AIs to have day-long horizons in 2028, week-long horizons in 2030, year-long horizons around 2035, and human-lifetime-long horizons around 2040.
But hidden in the paper is a surprising revelation: unofficially, progress might be speeding up:

METR writes:
The trend in 2024 and early 2025 may be faster, with o1 and Claude 3.7 Sonnet lying above the long-run trend. Though the gap is difficult to distinguish from noise, it is robust to methodological ablations like using continuous scoring.
Why would progress speed up?
Horizon growth since 2024, which may be faster than the long-term trend, could be explained by researchers post-training models to be more agentic (that is, capable of taking many sequential actions towards completing a task) using outcome-based RL. Research into making models capable and agentic is likely to continue. Future agency training could be faster than the long-run trend (since post-training may be more compute-efficient than pretraining at increasing horizon length). But 2024–2025 agency training could also be a one-time boost from picking low-hanging fruit, in which case horizon growth will slow once these gains are exhausted. Overall, we think agency training is more likely to increase the time horizon growth rate compared to the 2019–2024 trend.
In other words, people mostly weren’t thinking about planning horizons in 2020. Now that they’re the new big challenge in AI, companies have started attacking the problem on purpose. So far, it seems to be working.
Beyond the last horizon
So: extend the horizon growth trend line, see where it intersects with the human level, and that’s when we get AGI, right? What could be simpler?
But what is the human level? As we discussed above, humans don’t seem to have planning horizons in the same sense as AI2. In some sense, we have a practical horizon limited by the human lifespan. But if we somehow became immortal, we could - like the Bene Gesserit - have plans measured in centuries. Should we wait for the trend line to cross the human lifespan of ~80 years? To reach infinity? Neither seems very principled.
When humans succeed at a long-horizon task, we use certain abilities - memory, organization, planning, meta-learning - which let us treat big projects as a set of smaller subgoals. For example, when Mark Zuckerberg built Facebook from a dorm room to a global empire over twenty years, he worked on one stage at a time - programming the website, raising capital, hiring employees - maybe with a vague sketch in his head of "and one day I'm gonna get really big and then use all this attention to pioneer new ways of delivering news and opinions". When new possibilities arose (e.g. AI), he tried to weave them into the broader vision; when things fell apart (e.g. pivoting to the metaverse) he stepped back and regrouped. Instead of a single skill "have a twenty-year time horizon", he needed many smaller skills (coding, pitching to VCs, hiring) and meta-skills (learning new skills, combining skills, figuring out which skill to use).
If we take this seriously, we might expect progress in horizon length to be superexponential, as AIs start to figure out the meta-skills that let humans do projects of arbitrary length. That is, we would expect that it requires more new skills to go from a horizon of one second to one day, than it does to go from one year to one hundred thousand years; even though these are similar order-of-magnitude increases, we expect it to be easier to cross the latter gap. This superexponentiality is another potential reason why the 2024 - 2025 project is so much faster than the overall trend.
The most principled way to forecast AGI would be to figure out what all the various skills and meta-skills are, what horizon length represents mastery of those skills, and how we expect those skills to affect future progress. But we don’t know the answer to any of those questions, so we’re not going to be that principled.
METR’s solution was to pick the nice round number of one month:
We chose one month (approximately 167 working hours for a fair comparison with humans, since humans cannot work 24/7) for two reasons.
First, Ngo writes that a 1-month AGI (defined as an AI that outperforms most knowledgeable humans who are given 1 month of work hours, i.e. 167 hours, to perform the task) would necessarily exceed human performance both at tasks including writing large software applications or founding startups (clearly economically valuable), and including novel scientific discoveries.
Second, one month is around the period when new hires at a company begin to complete onboarding and generate economic value, and so an AI with a horizon of 1 month could be capable of acquiring context like a human employee, allowing it to complete high-context as well as low-context tasks.
METR, like ourselves, is interested in this question of when AIs can substitute for human programmers. Partly this is interesting because it might be the first big economic transformation - AIs seem on track to master coding before they master any other comparatively economically important sector. But partly it’s interesting because if there’s an intelligence explosion, superhuman coder AIs are probably when it starts in earnest.
If, like METR, you think a one-month horizon is a reasonable guess for economically transformative AI, you should expect to cross that threshold in a few years:

The longer 2019 - 2025 trend gets you transformative AI in 2030. The more recent, more speculative 2024 - 2025 trend gets you transformative AI in 20273.
Bells and whistles
We did the same calculation as METR, but ours was fancier. Where METR just extrapolated the trend line, we tried to forecast when the milestone would actually happen, given all the other factors involved. This took several adjustments.
First, instead of trusting any particular attempt to calculate the trend, we asked domain experts and superforecasters4 (people with a past track record of making good predictions) to look at all the paper as a gestalt and estimate the relevant parameters. For example, how long does it really take for horizons to double (Should we go with the overall trend of seven months? The more recent, faster trend? Something in between?). What horizon corresponds to our “superhuman coder” milestone? (Should we go with METR’s one month? Might it take longer? Does the horizon length on the METR task suite translate fluidly into real life?)
Second, instead of working with point estimates, we worked with probability distributions. For example, although one of our experts estimated that on average coding AIs would need a six week horizon to equal humans, he was able to be more specific by describing it as “a lognormal with 80% CI of [16 hours, 2 work-years (4,000 hours)].” You can see our full calculation here.
Third, we added a term for the possibility that the trend might change. One reason it might change is because the overall pattern is superexponential rather than exponential - the increased speed in 2024 - 2025 hints at this possibility, as does the “progress towards human-like unlimited horizons” argument discussed above. Another reason is the beginning of the intelligence explosion itself. Against these, there’s the usual low-hanging-fruit / diminishing returns argument that pushes in the direction of progress slowing down5.
Fourth, we added some extra terms for things like the delay between a company having an AI and deploying it externally.
Finally, METR was trying to estimate the arrival of “economically transformative AI”. But because we were interested in the beginning of the intelligence explosion, we estimated the arrival of “superhuman coders”, AIs capable of coding as well or better as the best humans (see the Defining A Superhuman Coder section of the Timelines Forecast for details). This is a higher standard than “mere” transformative AI, so we expected it to take longer time horizons.
When we ran the simulation, we got the following results:
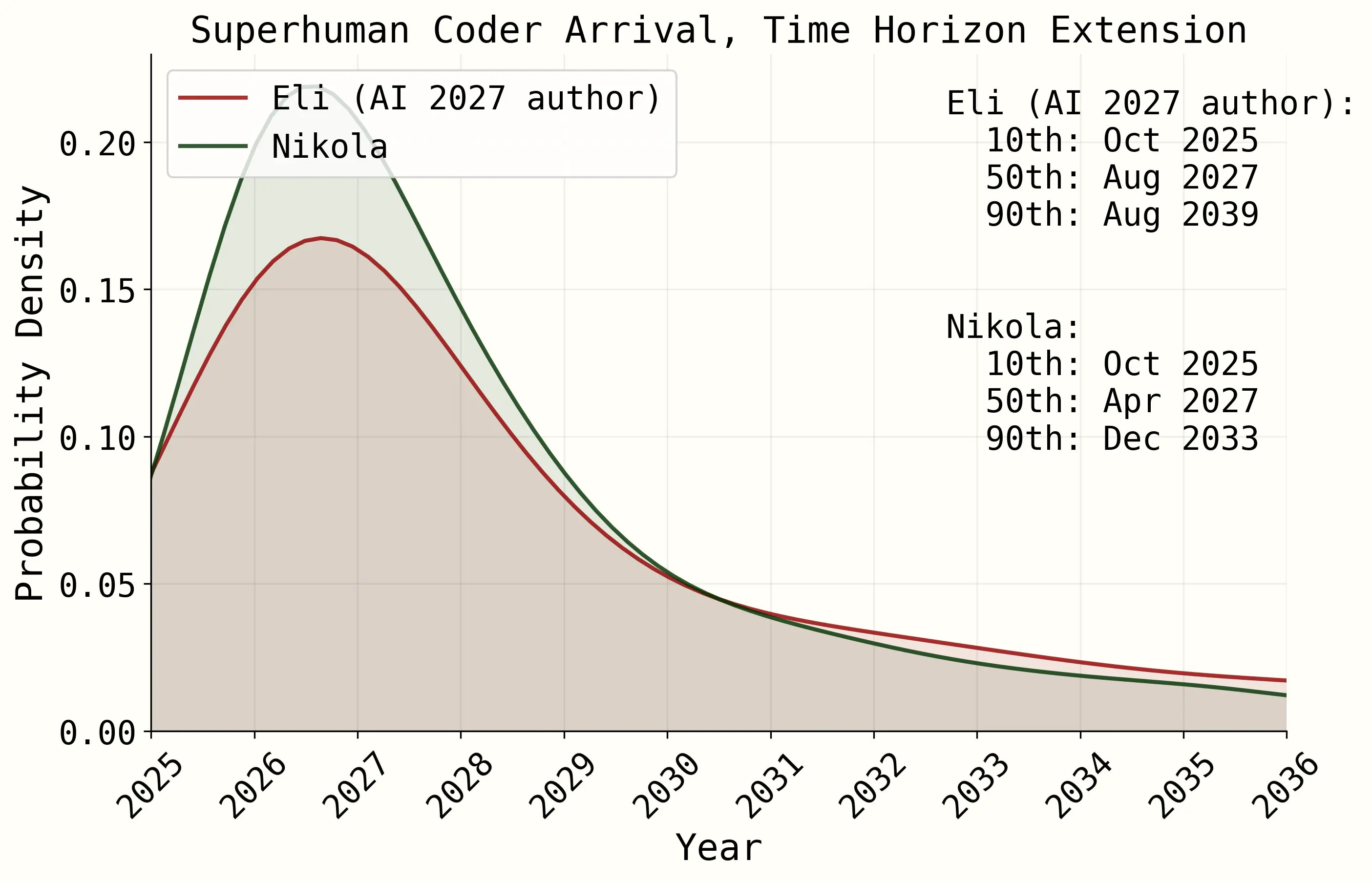
Eli is our in-house forecaster. Nikola is a domain expert (member of technical staff at METR) who kindly agreed to help with our estimate. Despite major disagreements about some parameters6, they ended up with similarly-shaped distributions, both peaking around 2027.
Then we tried some other stuff that also peaked in 20277, so that was nice and convenient and we named the scenario “AI 2027”.
Nice graphs, but what does any of this mean?
To summarize: METR finds that AIs are able to do quick tasks, but not long tasks. But they’re getting better at long tasks! So far it looks like they can do tasks of about 15 - 60 minutes, and that number doubles somewhere between every 3 - 7 months. These numbers are most applicable to coding, and uncertainty increases the further we go from that domain.
What horizon length do AIs need to match or exceed human coders? Nobody really knows, but if we make them guess, their guesses are usually in the range of months. Probably when they’re better than humans at some things they’ll still be worse at others, but at horizons of a few months they’ll probably be around vague parity.
So when will we have superhuman coders? If you’ve read the first two words of our scenario, you won’t be surprised to hear that our best guess is 2027, although with big error bars and multiple asterisks.
We think these human-level coders will be enough to start the intelligence explosion, which is why we place it in 2027 or 2028.
We hope this gives you a sense of our methodology, and how we aspire to be more than just a cool story that someone made up. You can read the more detailed version of all of this in the Timelines Forecast and the Time Horizon Appendix.
Cotra uses a definition somewhat different from ours, which descends more closely from Richard Ngo’s work described here.
“AIs have horizons but humans don’t“ is true in real life, but isn’t true by the specific formal definition that METR used, because the humans in the METR experiments tended to give up after a while if they couldn’t solve the problem. Technically METR found that humans had a “time horizon” of one hour, barely better than their AIs! We think this is just a finding about humans’ unwillingness to spend months working on fake tasks in an AI experiment for limited compensation, not a deeper truth about human abilities. See Footnote 6 in the Timelines Forecast for more in-depth discussion of this problem.
METR’s quick simulation predicts transformative AI in 2027, and our more complicated simulation also predicts superhuman coders in 2027, but this is kind of a coincidence. Our endpoint (superhuman coder) is more advanced than theirs (transformative AI). But we also give more weight to the possibility of a superexponential trend than they do, so our simulation has progress going faster, and both simulations reach their respective endpoints around the same time.
Like “Xerox” or “Kleenex”, the word “superforecaster” is both a brand name (the forecasters identified by Philip Tetlock and the Good Judgment Project) and a generic term (forecasters of approximately this caliber, identified using similarly rigorous methods). Here we use the term generically.
But in our model, diminishing returns don’t start kicking in until compute scaling slows in 2029.
Although Nikola’s predictions were straightforward, Eli’s 80th percentile confidence interval for the time horizon needed for superhuman coders was 1,200 years! On its face, this seems surprising - although we call it the “superhuman” coder, it’s only slightly beyond the best humans, and humans obviously don’t make 1,200 year plans. Eli explained that he’s not certain whether the METR experiments are a good proxy for real life, and he thinks that it might take 1,200 year horizons according to METR to get the few-month real-life horizons that he thinks are necessary. See the Time Horizon Appendix for more.
In the full model, our mode is 2027 but our median is later. See the first graph at the very beginning of the Timelines Forecast. Based on a more complete analysis, Eli got an median of December 2028, Nicola of October 2027, and FutureSearch (a forecasting company - we took the average of their three members) of January 2032.
Great work!
Nice graphs, but where is the CUMULATIVE probability?
That's the most relevant and easiest-to-read one on the "when superhuman coder", you could even combine the yearly and cumulative probabilities on one graph.
Nice that you included the 10/50/90th percentile data points but a curve would be better.
Again, great work!
>But what is the human level? As we discussed above, humans don’t seem to have planning horizons in the same sense as AI
This is true, but if I had to choose a practical limit, I'd pick around 5 years. Many, many human institutions choose horizons about this long. Political term limits. Time spent in a single school or degree program. Development time for a car model or other complex product (though it varies from months for clothes to decades for planes, depending on industry constraints and standards). If I had to pull a reason out of nowhere, I'd say that's a little longer than how far apart our hunter-gatherer ancestors spaced having children, which was probably the single longest term kind of project we undertook in the distant past. Later on our elders and dynastic leaders undertook projects with much longer time horizons, including beyond their own lifetimes, but in large part that was about setting their own descendants up for success.