
Making sense of OpenAI's models
Plus: GPT-5's secret identity


We’re not the only people who get confused by OpenAI model names.
There’s actually a simple explanation: most of the models are modifications of each other in a giant dependency graph that OpenAI is keeping secret. In this post we’ll dive into explaining our best guess on how that graph looks.1
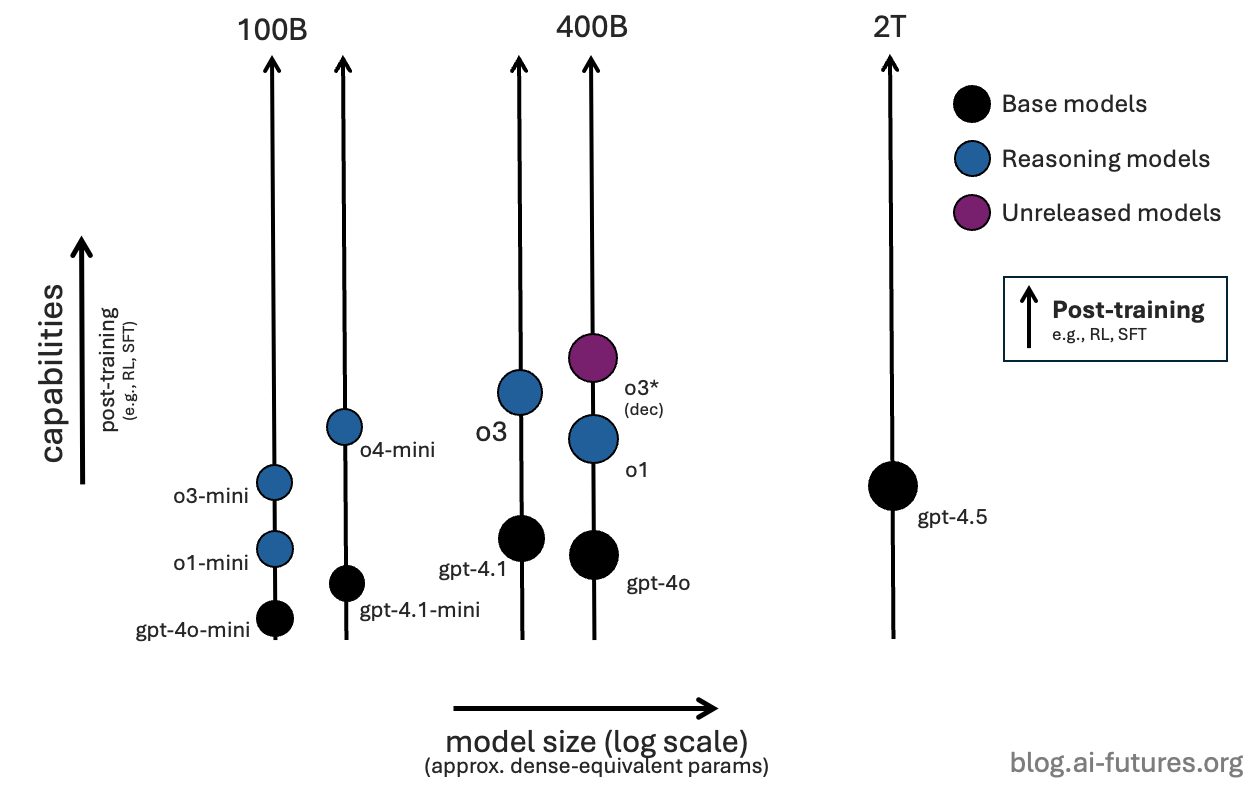
Backing up: all AIs start with a base model. Base models trained with more compute are usually bigger and better. OpenAI’s recent base models include GPT-4o, GPT-4.1, and GPT-4.5.2
Sometime around 2023-2024, OpenAI started to reasoning-train their base models using some combination of reinforcement learning on auto-graded problems, and fine-tuning on high quality data.3
Their reasoning prototype was called o1-preview, followed by o1. These models vastly improved upon GPT-4o in problem-solving domains like math, coding, and science.4
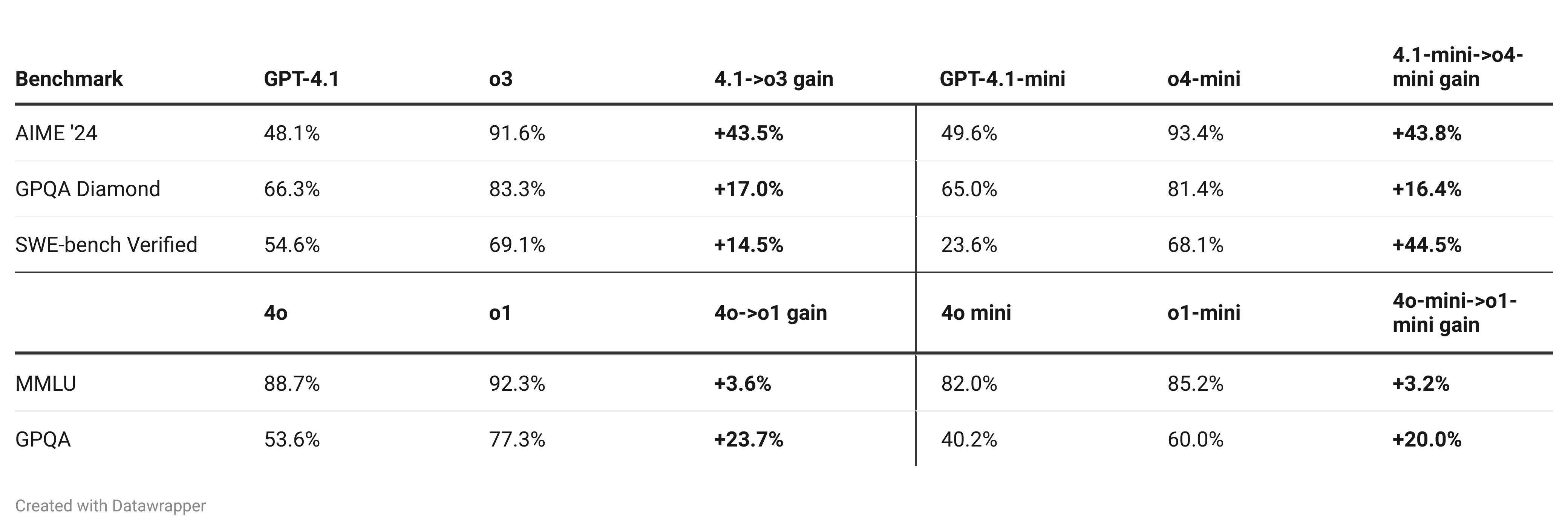
Finally, researchers can also train smaller models on a big model’s output, in a process called distillation. This can boost performance to be almost as good as the bigger parent model for a fraction of the cost. OpenAI tends to call its smaller models “mini”, as in GPT-4o-mini, GPT-4.1-mini, and their corresponding post-trained reasoning models o1-mini, o3-mini, and o4-mini.
The pandemonium of OpenAI offerings are all some kind of base model plus some number of reasoning-trainings and distillations. Which base model, and how many post-trainings and distillations? OpenAI doesn’t tell us, but we have two ways to make educated guesses.
Knowledge cutoff: Each base model has a knowledge cutoff based on when it was pre-trained. A reasoning model with a different knowledge cutoff is very unlikely to come from that same base model.5
API pricing: Bigger models cost more, so models with similar cost are probably similarly sized.
Putting these two strategies together, here’s our best guess about the true identity of each OpenAI offering.
And here’s an animation of how they might have evolved:

Reality is probably different to this animation, but we think a good general heuristic is that they have been eliciting their smartest model(s) to distill into active post-training runs.
Why are there two o3s?
In December 2024, OpenAI announced a model called o3 with very impressive scores on ARC-AGI and other benchmarks. In February 2025, they announced that they would not be releasing o3 independently, instead planning to “integrate the technology” into GPT-5.
Then in April, they reversed course, saying there was a “change in plans” and “we are going to release o3 . . . after all”, which they did two weeks later.
But the o3 they released had substantially different benchmark scores from the one they teased in December. The difference is most stark on ARC-AGI, which also report:
They confirmed that this public o3 model differs from the o3-preview we tested in December 2024. - ARC-AGI.
So what happened?
We think the original o3, like o1, was a post-trained version of GPT-4o. Maybe it used a newer version of 4o, or they just post-trained for longer, or both. Original o3 (dec) achieved these benchmark scores with very large amounts of inference-time compute (100x more compute than o3 (apr) on ARC-AGI).6 This was so expensive that it wouldn’t work as a commercial offering,7 so they decided to skip a public release of o3 and go straight to GPT-5.
Later, pre-training of the cheaper GPT-4.1 and GPT-4.1-mini models went well, so they decided to post-train them and release the resulting models. These took on the next available names in their series: o3 and o4-mini.
We don’t think OpenAI was intentionally lying or covering anything up - just that it suited their purposes to use the name for one model last year and a different model this April.
An alternative hypothesis
We also considered that the o3 we saw back in December was already a post-trained GPT-4.5. But this feels less likely due to rumors from The Information and how compute-intensive this would have been in a short time period, but we aren’t confident.
Now, with next generation Nvidia chips online since Jan 2025, we think they are on track to pull off post-training on a GPT-4.5 scale model. In fact, it’s our leading candidate for what they will call GPT-5.
GPT-5’s Secret Identity
We think GPT-5 will be GPT-4.5—or a new similarly-sized base model—plus post-training; something like GPT-4.5-reasoning in our naming scheme above.
A top goal for us is to unify o-series models and GPT-series - Sam Altman
Under our forecasts we expect them spend around $2 billion on compute for GPT-5 (1e27 FLOP).8 They’ll need to split this $2 billion into pre-training (predicting the next token in massive internet text corpuses) and post-training.
What is the optimal pre-training to post-training ratio? The AI companies probably aren’t sure, and whatever clues they have are among their most important trade secrets. It’s probably somewhere in the range of 20% - 90% post-training, but depending on where in that range they’re thinking, OpenAI will be considering several options:9
Train a larger base model: If they want something like 20% post-training, then the 80% that goes to pre-training will be enough to make a model 2-3x the size of GPT-4.5. Would this be worth it, or would they just use GPT-4.5 instead? We’re not sure.
Post-train GPT-4.5. If they want more like 50% post-training, then the 50% that goes to pre-training will only be enough to make another model around the same size as GPT-4.5. Maybe they would just use GPT-4.5 itself - although if they’re unhappy with GPT-4.5, they could train a fresh model.10
Distill GPT-4.5. If they want more like 90% post-training, they’ll need to start with a smaller base model than GPT-4.5 - this could be a GPT-4.5-mini, which would still be larger than GPT-4o -and post-train on that.
Out of these possibilities we think Option 2 is slightly more likely since scaling to a larger base model or a multi-billion dollar post-training run both seem significantly more challenging.
How good will GPT-5 be?
Is there a scaling law for post-training improvements?
We think GPT-4.5 is probably around 5 times bigger that GPT-4o.11 And we know that reasoning models outperform their bases, especially on coding, science and math.
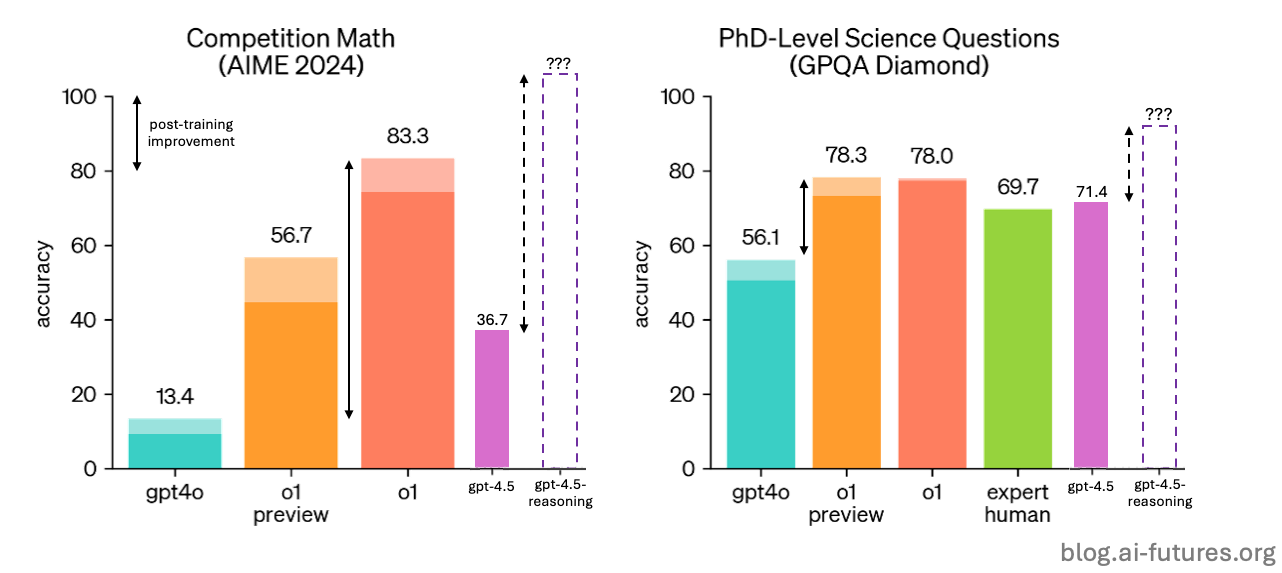
So a reasoning model trained on GPT-4.5 has the potential to be very impressive.
But the exact gains depend on how post-training improvements scale with model size. So far, little is known about the nature of these scaling laws. All we have are some murky arguments and inconclusive evidence from the improvement gaps between o series and o-mini series models.12 So for now, we’re limited to more theoretical arguments:
Argument 1: Bigger is better
There’s a loose argument that post-training will be more effective on larger models because they provide a better ‘foundation’. Here’s how OpenAI phrased it:
As models like GPT‑4.5 become smarter and more knowledgeable through pre-training, they will serve as an even stronger foundation for reasoning and tool-using agents. — OpenAI
This is not particularly compelling, but maybe feels more intuitive than the inverse.
Argument 2: The post-training data wall
It’s plausible that we should think of post-training as pushing models up towards some notion of a ceiling that gets determined by the quality of the data and reward signal provided. If current RL runs are already getting close to that wall, then larger models will struggle to see the same gains as smaller ones.13
Argument 3: Agency post-training is untapped
Even if Argument 2 were true, it’s probably only true for the problem solving tasks like coding, math, and science, where more low hanging fruit has been picked. But we haven’t yet seen post-training for performing longer tasks autonomously and reliably (e.g., making updates across a codebase, navigating files, putting together a fully researched presentation, etc.). If gains from reasoning training peter out, OpenAI might shift some of its RL focus to agency training, where gains are still unrealized.
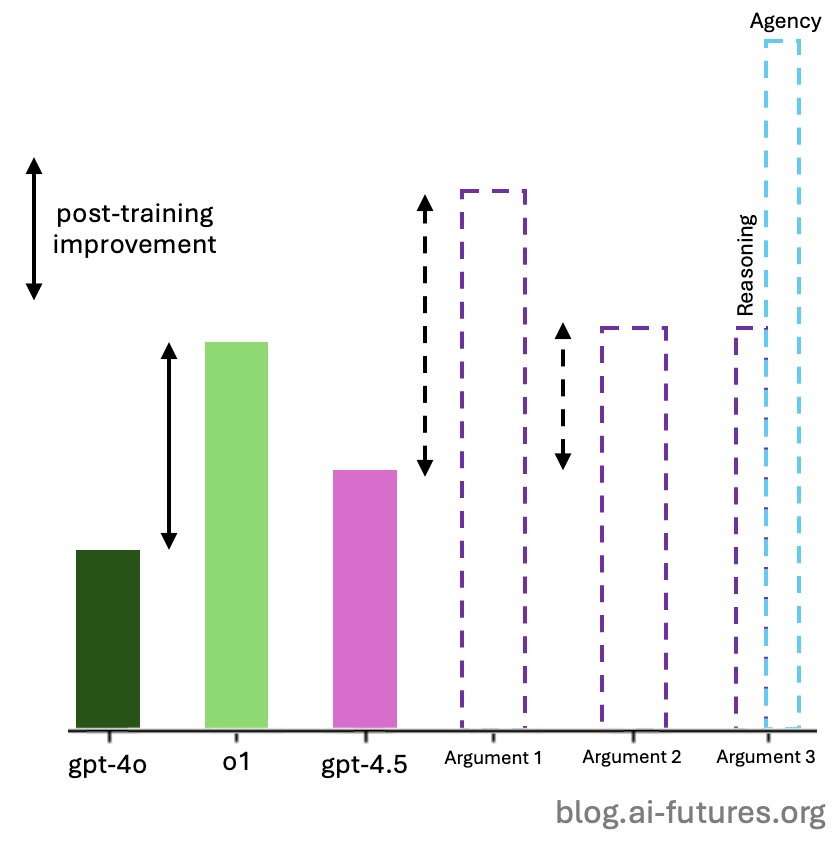
We hope to learn more about these post-training scaling laws after GPT-5; for now, the jury is out.
Open Secrets
What are we even doing here?
It would be nice to think of ourselves as investigators, blowing the lid on corporate secrets. But none of this really matters. OpenAI hasn’t hidden these details because they’re dangerous. Maybe they contain slight clues about the GPT training process, but Anthropic, Google, DeepSeek, etc. probably figured this all out long before we did. We doubt OpenAI had any specific motivation beyond a general corporate culture of secrecy.
In our scenario, this culture of secrecy proves deadly. AI companies initiate an intelligence explosion behind closed doors, without Congress or the public getting a chance to respond. One of our biggest wish list items is more transparency - whether voluntary or enforced by regulation - so we (or at least some government body) know what’s being trained, how capable it is, and what steps are being taken to test and monitor it. We at least want whistleblower protection, to give us an extra chance of learning if something bad is going on.
We won’t get that in time for GPT-5, but we hope to get it in time for later models.
Though his insider knowledge is out of date anyway, Daniel recused himself from giving input into this post.
These aren’t literally raw pre-trained models. They have some post-training in the form of instruction tuning, RLHF, or similar, but unlike reasoning models, post-training is likely to be <5% of total training compute, so we are calling them base models.
In the reinforcement learning (RL) setup, rather than trying to ‘predict the next token’ as in pre-training, the model is given a difficult problem to solve using a ‘chain of thought,’ and then its answer gets graded. Successful solutions are reinforced, and poor solutions are optimized against. Of course, this setup requires the problems to be easily verifiable, so that huge amounts of reasoning traces can be auto-graded for success.
In the fine-tuning (SFT) setup, they generate high quality solutions to hard problems by putting their smartest models in expensive inference-time scaffolds (which can be as simple as taking the most common answer out of 1000 attempts, known as cons@1000). This process—called elicitation—produces a synthetic dataset of high quality examples to train on.

We don’t think they can update the knowledge cutoff with post-training. It’s plausible they update a base model by scraping bunch of new internet data and doing more pre-training, but the resulting new checkpoint would effectively be a ‘new’ base model
We know from ARC-AGI estimates that o3 (high) (dec), used 1024 sample size, with 172x compute, generating ~300k tokens per task. This is 100x more expensive than the o3 (apr) that was released.
o1-pro already costs $150 / $600 in the API (input / output) per million tokens
In 2025, this gives them about 1e27 FLOP to work with, or 50xGPT-4
We know DeepSeek’s R1 was around 20% post-training, and this feels like it should be a rough lower bound for what to expect for GPT-5, given their plans to “unify o-series models and GPT-series models.” Also, in his January 2025 piece on On DeepSeek and Export Controls, Dario Amodei, implied that current RL runs were somewhere in the $1M to $100M range:
“Importantly, because this type of RL is new, we are still very early on the scaling curve: the amount being spent on the second, RL stage is small for all players. Spending $1M instead of $0.1M is enough to get huge gains. Companies are now working very quickly to scale up the second stage to hundreds of millions and billions…”
We are guessing that OpenAI are already pushing into this ‘hundreds of millions’ to (low) 'billions’ range as of today.
GPT-4.5 seems like it has some promising properties (e.g., low hallucination rate, and deep world knowledge) that makes it a good candidate for post-training, but it also had relatively weak performance on benchmarks, broadly eclipsed by the much cheaper GPT-4.1.
We arrive at the rough 5x model size estimate from the ~15x output token cost because we estimate that current inference economics shake out in favor of the smaller models greater than strict proportionality would dictate. The most relevant resource for serving a model is memory bandwidth of the AI hardware, given that each token generation needs to move the model weights and kv cache into logic. The size of the model roughly scales these both proportionally, but the larger model is generally more challenging to handle due to chip-to-chip communication bottlenecks from needing to spread weights over more total GPUs compared to the smaller model. We also guess they might be doing a larger markup on GPT-4.5 API pricing to discourage too much usage, so that they can reserve GPU capacity (note that they announced with the release of the GPT-4.1 series that they are discontinuing GPT-4.5 in the API soon for this exact reason).
Helen Toner has a recent helpful writeup about this question of how far RL will scale, including to other domains, and on the prospects for training on verifiable domains to generalize.
Ok actually one more.
Hallucination rate (PersonQA) could be a pretty good way to measure size of models as well, more parameters means more spots to “store” random knowledge- this would explain the placement of the mini models, 4o, and 4.5
So the (seemingly weirdly) poor o3 performance on PersonQA could mean one of two things
1. It really is just a smaller model, this would explain the pricing as well, however, the system card thinks it’s a weird finding.
2. Sufficiently advanced levels of RL “corrupt” some of the inner knowledge.
Something that I never got was the relationship between GPT-4 and GPT-4o, is it a different base model?